
Introduction#
Self-attention-based architectures, such as Transformers, were initially developed for natural language processing. In contrast, convolutional neural networks (CNNs) have long dominated computer vision tasks.
Attempts to integrate self-attention with convolutional models initially yielded poor results. The Vision Transformer (ViT) introduces a new approach by splitting an image into patches, linearly embedding each patch, and feeding the resulting sequence into a standard Transformer.
- Patch \( \approx \) Token
- Poor performance on mid-sized datasets like ImageNet
- Lacks inductive biases present in CNNs:
- Translation equivariance: outputs shift consistently with translated inputs
- Locality: emphasizes spatially adjacent features
However, with sufficiently large datasets, ViTs achieve strong performance.
Methodology#
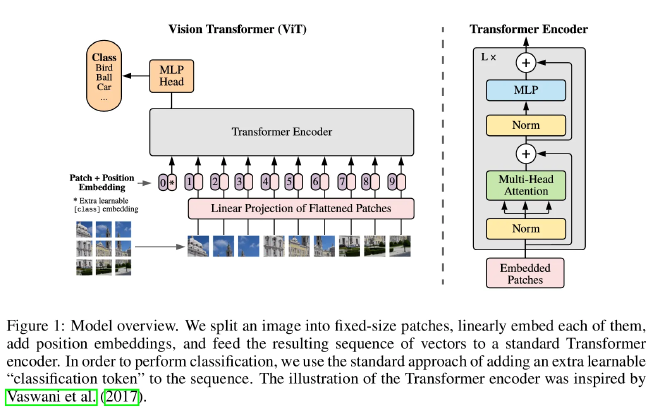
Vision Transformer (ViT)#
Patch Embedding:
- Flatten the input image into non-overlapping fixed-size patches.
- Linearly project each patch into a vector.
- \( \mathbf{x}_p \in \mathbb{R}^{H \times W \times C} \rightarrow \mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)} \), where \( N \) is the number of patches.
- Each patch is projected to a constant latent dimension \( D \).
Class Token:
- A learnable classification token ([CLS]) is prepended to the input sequence.
- Acts as an aggregate representation, similar to BERT.
Positional Embedding:
- 1D learnable positional embeddings are added to retain spatial order.
- 2D positional embeddings offer limited additional benefit.
Transformer Encoder:
- Composed of alternating layers of multi-headed self-attention (MSA) and MLP blocks.
- Includes residual connections and LayerNorm.
Classification Head:
- The final representation of the [CLS] token is passed through an MLP for classification.
Architecture#
$$ z_0 = [x_{\text{class}}; x_p^1 E; x_p^2 E; \cdots; x_p^N E] + E_{\text{pos}} \tag{1} $$
$$ E \in \mathbb{R}^{(P^2 \cdot C) \times D}, \quad E_{\text{pos}} \in \mathbb{R}^{(N+1) \times D} $$
$$ z_{\ell}’ = \mathrm{MSA}(\mathrm{LN}(z_{\ell - 1})) + z_{\ell - 1}, \quad \ell = 1, \ldots, L \tag{2} $$
$$ z_{\ell} = \mathrm{MLP}(\mathrm{LN}(z_{\ell}’)) + z_{\ell}’, \quad \ell = 1, \ldots, L \tag{3} $$
$$ y = \mathrm{LN}(z_L^0) \tag{4} $$
Inductive Biases in ViT#
Though ViT lacks explicit inductive biases like CNNs, the architecture learns both local and global features:
- MSA captures long-range dependencies.
- MLP layers encourage local interactions.
Hybrid ViT-CNN Architecture#
Instead of using image patches, ViT can ingest CNN feature maps as input sequences to combine benefits of both architectures.
Fine-Tuning on Higher Resolution#
Pretrained ViTs on lower-resolution images can be fine-tuned on higher-resolution inputs:
- Patch size remains fixed, increasing the sequence length.
- 2D interpolation aligns the learned positional embeddings with the new input resolution.
Experimental Results#
Experimental Setup#
- Pretraining Datasets:
- ImageNet (1.3M images)
- ImageNet-21k (14M images)
- JFT-300M (303M images)
- Evaluation Benchmarks:
- ImageNet, CIFAR-10/100, VTAB (19 tasks), Oxford Pets, Flowers-102
- Model Variants:
- ViT-Base, ViT-Large, ViT-Huge
- Baselines:
- Compared against ResNet (BiT) and Noisy Student (EfficientNet)
Key Findings#
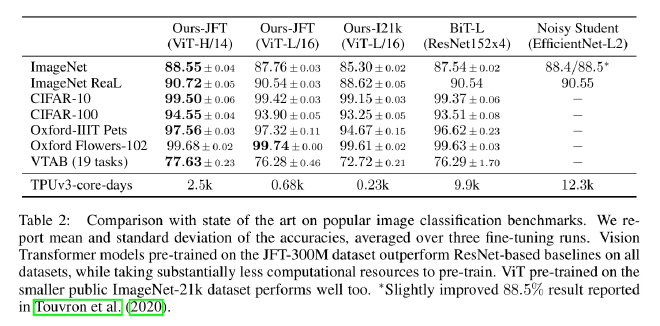
Performance:
- ViTs match or surpass state-of-the-art CNNs when pretrained on large datasets.
- ViT-H/14 achieves:
- 88.55% on ImageNet
- 94.55% on CIFAR-100
- 77.63% on VTAB
Compute Efficiency:
- ViT-H/14 outperforms ResNet-based models while using significantly fewer compute resources (2.5k vs. 9.9k TPUv3-core-days).
Data Requirements:
- ViTs underperform CNNs on small datasets.
- Performance improves markedly with larger-scale data.
Scalability:
- Increasing model depth, width, or patch size improves performance.
- No clear signs of saturation even for very large models.
Few-Shot Learning:
- ViTs show strong performance on few-shot classification, benefiting from large-scale pretraining.
Self-Supervised Learning (Preliminary Results):
- Masked patch prediction improves accuracy by ~2% on ImageNet.
- Still lags behind supervised pretraining in overall performance.
Attention Visualization:
- ViTs exhibit both local and global attention patterns.
- Positional embeddings capture spatial topology despite lacking explicit structure.
Conclusion#
Vision Transformers, though originally lacking image-specific inductive biases, achieve strong and often superior performance compared to CNNs when trained on large datasets. They scale effectively, are compute-efficient, and perform well in both few-shot and self-supervised settings. Their ability to model both local and global dependencies makes them a promising architecture for future vision tasks.